字节对齐
字节对齐
本文介绍 C/C++ 结构体字节对齐规则和处理。
字节对齐
1 字节对齐概念
现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐。
变量存的起始地址必须具备某些特性——“对齐”,比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除。对齐跟数据在内存中的位置有关。为了使得CPU能快速对变量进行访问,变量存的起始地址必须具备某些特性,即“对齐”,比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除。
2 字节对齐理由
2.1 不同硬件平台对存储空间的处理上存在不同
某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。
2.2 根本原因在于CPU访问数据的效率问题
以32位机为例,它每次取32个位,也就是4个字节。以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如果不对齐,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,这样效率也就降低了。

2.3 节约空间
应该辩证地看:合理对齐,则节约空间;否则浪费空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <iostream>
typedef struct Test1
{
int pub_int;
short pub_short;
char pub_char;
} Test1;
typedef struct Test2
{
char pub_char;
int pub_int;
short pub_short;
} Test2;
typedef struct Test3
{
char pub_char;
short pub_short;
int pub_int;
} Test3;
int main()
{
// #define offsetof(struct, field) (size_t)&(((struct*)0)->field)
printf("The Sturct Test1 Size: %2ld, Offset: %2ld, %2ld, %2ld\n", sizeof(Test1), offsetof(Test1, pub_int), offsetof(Test1, pub_short), offsetof(Test1, pub_char));
printf("The Sturct Test2 Size: %2ld, Offset: %2ld, %2ld, %2ld\n", sizeof(Test2), offsetof(Test2, pub_char), offsetof(Test2, pub_int), offsetof(Test2, pub_short));
printf("The Sturct Test3 Size: %2ld, Offset: %2ld, %2ld, %2ld\n", sizeof(Test3), offsetof(Test3, pub_char), offsetof(Test3, pub_short), offsetof(Test3, pub_int));
}
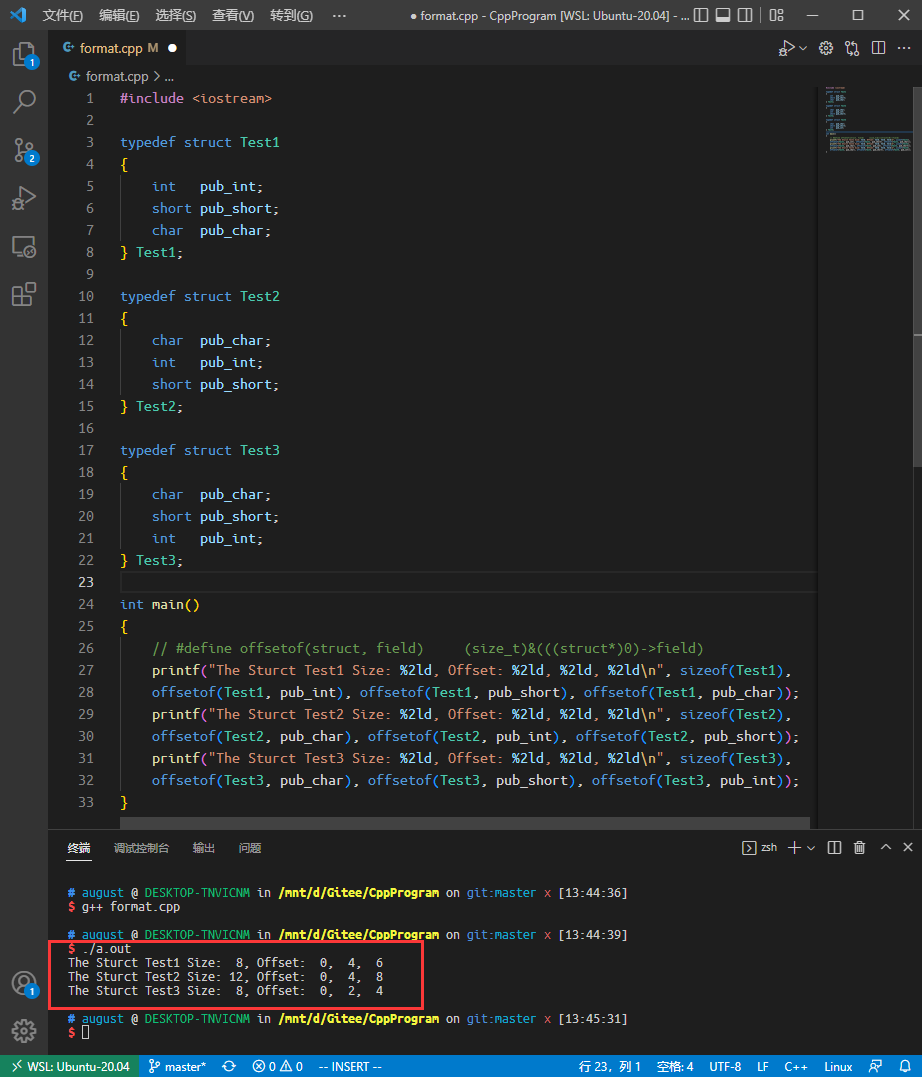
结构体Test1中包含一个4字节的int数据,一个1字节char数据和一个2字节short数据;Test2、Test3也一样。按理说Test1、Test2、Test3的大小应该都是7字节。之所以出现上述结果,就是因为编译器要对数据成员在空间上进行对齐。
3 字节对齐标准
3.1 对齐准则
- 结构体变量的首地址能够被其对齐字节数大小所整除。
- 结构体每个成员相对结构体首地址的偏移都是成员大小的整数倍,如不满足,对前一个成员填充字节以满足。
- 结构体的总大小为结构体对齐字节数大小的整数倍,如不满足,最后填充字节以满足。
64 位机器变量字节
| 类型 | 字节 | 范围 |
|---|---|---|
| char | 1 | -128~127 |
| unsigned char | 1 | 0~256 |
| (signed) short | 2 | -32768~32767 |
| unsigned short | 2 | 0~65536 |
| (signed) int | 4 | -2147483648~2147483647 |
| unsigned int | 4 | 0~4294967295 |
| (signed) long | 8 | -9223372036854775808~9223372036854775807 |
| unsigned long | 8 | 0~18446744073709551615 |
| (signed) long long | 8 | -9223372036854775808~9223372036854775807 |
| unsigned long long | 8 | 0~18446744073709551615 |
| float | 4 | 1.175494351e-38F~3.402823466e+38F |
| double | 8 | 2.2250738585072014e-308~1.7976931348623158e+308 |
| long double | 16 | |
| wchar_t | 4 | -2147483648~2147483647 |
| 所有指针 | 8 | |
| bool | 1 | true/false |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <cfloat>
#include <climits>
#include <iostream>
int main()
{
printf("char: %2ld, (%20d, %20d)\n", sizeof(char), CHAR_MIN, CHAR_MAX);
printf("short: %2ld, (%20d, %20d)\n", sizeof(short), SHRT_MIN, SHRT_MAX);
printf("int: %2ld, (%20d, %20d)\n", sizeof(int), INT_MIN, INT_MAX);
printf("long: %2ld, (%20ld, %20ld)\n", sizeof(long), LONG_MIN, LONG_MAX);
printf("long long: %2ld, (%20lld, %20lld)\n", sizeof(long long), LONG_LONG_MIN, LONG_LONG_MAX);
printf("float: %2ld, (%20f, %f)\n", sizeof(float), FLT_MIN, FLT_MAX);
printf("double: %2ld, (%20lf, %lf)\n", sizeof(double), DBL_MIN, DBL_MAX);
// printf("long double: %2ld, (%20Lf, %Lf)\n", sizeof(long double), LDBL_MIN, LDBL_MAX);
printf("wchar_t: %2ld, (%20d, %20d)\n", sizeof(wchar_t), WCHAR_MIN, WCHAR_MAX);
printf("pointer: %2ld\n", sizeof(char*));
printf("pointer: %2ld\n", sizeof(int*));
printf("bool: %2ld\n", sizeof(bool));
}
3.2 对齐隐患
在不同系统因为对齐方式和大小可能不一样,对于强制类型转换就会出现问题,以及根据偏移取字段。
建议使用 #include <cstdint> 二次封装大小在不同位数系统上交互时。
1
2
3
4
5
6
7
8
#include <cstdint>
int16_t a;
uint16_t ua;
int32_t b;
uint32_t ub;
int64_t c;
uint64_t uc;
3.3 指定对齐方式
1
2
#pragma pack(n) // 设置n字节对齐
#pragma pack() // 取消自定义字节对齐方式
- 组建网络报文格式
- 序列化和反序列化
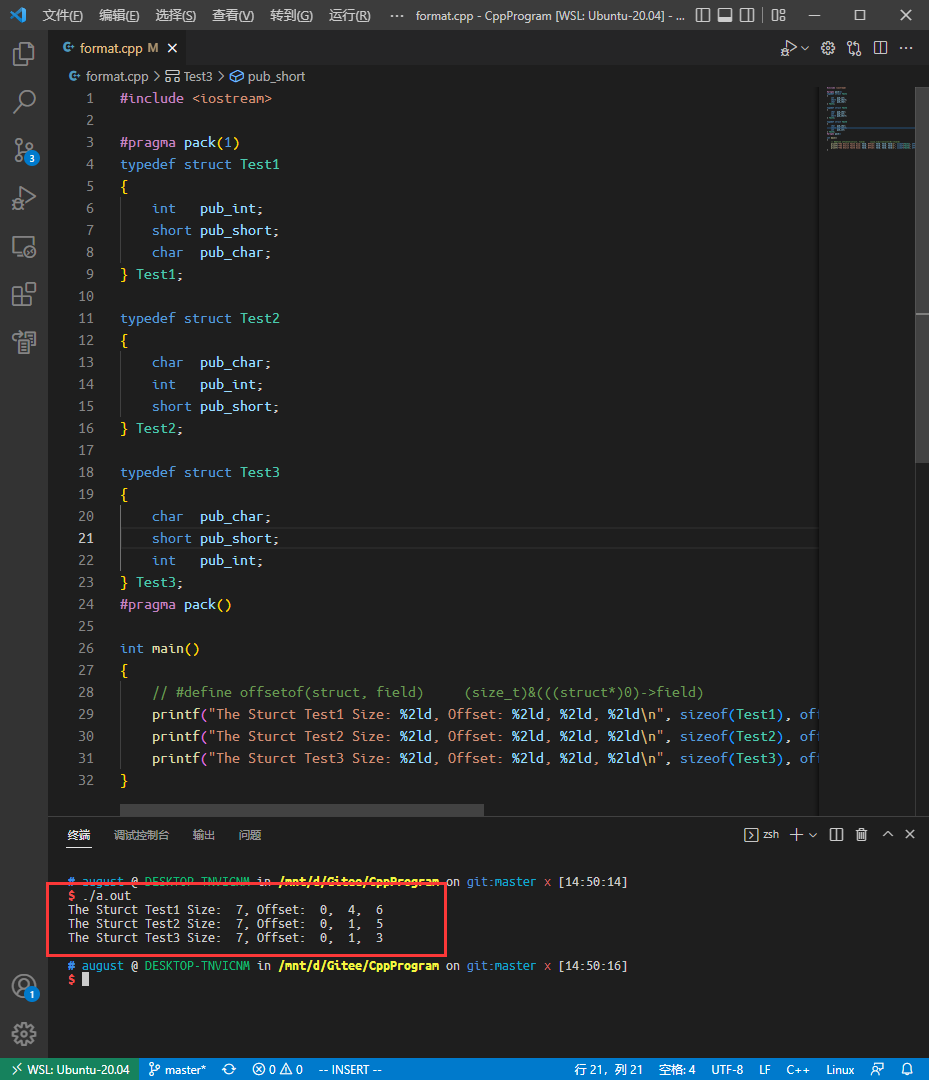
在节约空间中将结构体前后添加 #pragma pack(1) 和 #pragma pack() 即可得到完全紧凑排列。
参考
本文由作者按照 CC BY 4.0 进行授权