MoreEffectiveC++笔记
该文记录《More Effective C++》读后记录。
More Effective C++
35个改善编程与设计的有效方法
1. 基础议题
1.1. Item M1:指针与引用的区别
指针用操作符 * 和 ->,引用使用操作符 .。指针与引用都是让你间接引用其他对象。
要认识到在任何情况下都不能使用指向空值的引用。一个引用必须总是指向某些对象。
因为引用肯定会指向一个对象,引用应被初始化。
指针可以被重新赋值以指向另一个不同的对象。但是引用则总是指向在初始化时被指定的对象,以后不能改变。
指针使用情况
- 你考虑到存在不指向任何对象的可能(在这种情况下,你能够设置指针为空)
- 需要能够在不同的时刻指向不同的对象(在这种情况下,你能改变指针的指向)
引用使用情况
- 总是指向一个对象并且一旦指向一个对象后就不会改变指向
- 重载某个操作符时(
[])
当你知道你必须指向一个对象并且不想改变其指向时,或者在重载操作符并为防止不必要的语义误解时,你不应该使用指针。而在除此之外的其他情况下,则应使用指针。
1.2. Item M2:尽量使用 C++风格的类型转换
C++通过引进四个新的类型转换操作符克服了 C 风格类型转换的缺点,这四个操作符是 static_cast, const_cast, dynamic_cast, 和 reinterpret_cast。
static_cast在功能上基本上与C风格的类型转换一样强大,含义也一样。dynamic_cast用于安全地沿着类的继承关系向下进行类型转换。const_cast用于类型转换掉表达式的const或volatileness属性。reinterpret_casts的最普通的用途就是在函数指针类型之间进行转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// static_cast
double result = static_cast<double>(firstNumber)/secondNumber;
// dynamic_cast
class Widget { ... };
class SpecialWidget: public Widget { ... };
void update(SpecialWidget *psw);
update(dynamic_cast<SpecialWidget*>(pw));
// const_cast
SpecialWidget sw; // sw 是一个非 const 对象。
const SpecialWidget& csw = sw; // csw 是 sw 的一个引用,它是一个 const 对象
update(const_cast<SpecialWidget*>(&csw)); // 正确,csw 的 const 被显示地转换掉( csw 和 sw 两个变量值在 update 函数中能被更新)
// reinterpret_casts
typedef void (*FuncPtr)(); // FuncPtr is 一个指向函数的指针,该函数没有参数返回值类型为 void
FuncPtr funcPtrArray[10]; // funcPtrArray 是一个能容纳 10 个 FuncPtrs 指针的数组
funcPtrArray[0] = reinterpret_cast<FuncPtr>(&doSomething);
1.3. Item M3:不要对数组使用多态
类继承的最重要的特性是你可以通过基类指针或引用来操作派生类。
1
2
3
4
5
6
7
8
9
10
11
// 假设你有一个类 BST(比如是搜索树对象)和继承自 BST 类的派生类 BalancedBST:
class BST { ... };
class BalancedBST: public BST { ... };
void printBSTArray(ostream& s, const BST array[], int numElements);
BST BSTArray[10];
printBSTArray(cout, BSTArray, 10); // 运行正常
BalancedBST bBSTArray[10];
printBSTArray(cout, bBSTArray, 10); // 运行异常
编译器为了建立正确遍历数组的执行代码,它必须能够确定数组中对象的大小,派生类对象大小与基类对象大小不一致。
1.4. Item M4:避免无用的缺省构造函数
缺省构造函数(指没有参数的构造函数)。
缺省构造函数使用情况:
- 建立数组:可以用指针实现来避免
- 基于模板(template-based)的容器类里使用:需要模板类作者实现兼容来避免
- 虚基类和派生类:派生类必须知道并理解虚基类构造函数参数的含义来避免
1
2
3
4
5
6
7
8
class EquipmentPiece {
public:
EquipmentPiece(int IDNumber);
};
// 建立数组
typedef EquipmentPiece* PEP; // PEP 指针指向一个 EquipmentPiece 对象
PEP bestPieces[10]; // 正确, 没有调用构造函数
因为这些强加于没有缺省构造函数的类上的种种限制,一些人认为所有的类都应该有缺省构造函数,即使缺省构造函数没有足够的数据来完整初始化一个对象。
使用这种(没有缺省构造函数的)类的确有一些限制,但是当你使用它时,它也给你提供了一种保证:你能相信这个类被正确地建立和高效地实现。
2. 运算符
2.1. Item M5:谨慎定义类型转换函数
C++ 编译器能够在两种数据类型之间进行隐式转换(implicit conversions)。
有两种函数允许编译器进行这些的转换:单参数构造函数(single-argument constructors)和隐式类型转换运算符。
- 单参数构造函数是指只用一个参数即可以调用的构造函数。该函数可以是只定义了一个参数,也可以是虽定义了多个参数但第一个参数以后的所有参数都有缺省值。
- 隐式类型转换运算符只是一个样子奇怪的成员函数:
operator关键字,其后跟一个类型符号。
1
2
3
4
5
6
7
8
9
10
11
class Rational { // 有理数类
public:
Rational(int numerator = 0, int denominator = 1); // 转换 int 到有理数类
operator double() const; // 转换 Rational 类成 double 类型
};
// 单参数构造函数
// 隐式类型转换运算符
Rational r(1, 2); // r 的值是 1/2
double d = 0.5 * r; // 转换 r 到 double, 然后做乘法
explicit关键字,编译器会拒绝为了隐式类型转换而调用构造函数。- 通过不声明运算符(operator)的方法,可以克服隐式类型转换运算符的缺点
2.2. Item M6:自增(increment)、自减(decrement)操作符前缀形式与后缀形式的区别
C++ 语言得到了扩展,允许重载 increment 和 decrement 操作符的两种形式。不论是 increment 或 decrement 的前缀还是后缀都只有一个参数。为了解决这个语言问题,C++ 规定后缀形式有一个 int 类型参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// "unlimited precision int"
class UPInt
{
public:
UPInt& operator++(); // ++ 前缀
const UPInt operator++(int); // ++ 后缀
UPInt& operator--(); // -- 前缀
const UPInt operator--(int); // -- 后缀
};
// 前缀形式:增加然后取回值
UPInt& UPInt::operator++()
{
*this += 1; // 增加
return *this; // 取回值
}
// 后缀形式:取回值然后增加
const UPInt UPInt::operator++(int)
{
UPInt oldValue = *this; // 取回值
++(*this); // 增加
return oldValue; // 返回被取回的值
}
- 前缀形式返回一个引用,后缀形式返回一个
const类型 - 返回类型包含
const表示不可再修改 i++++不允许,去掉const可以实现,但是结果只增加了一,与期望不一致
2.3. Item M7:不要重载“&&”,“||”, 或“,”
C++ 使用布尔表达式短路求值法(short-circuit evaluation)。
你不能重载下面的操作符:
| . | .* | :: | ?: |
|---|---|---|---|
| new | delete | sizeof | typeid |
| static_cast | dynamic_cast | const_cast | reinterpret_cast |
你能重载:
| operator new | operator delete | operator new[] | operator delete [] |
|---|---|---|---|
| + | - | * | / |
| % | ^ | & | | |
| ~ | ! | = | < |
| > | += | -= | *= |
| /= | %= | ^= | &= |
| |= | « | » | »= |
| «= | == | != | <= |
| >= | && | || | ++ |
| – | , | ->* | -> |
| () | [] |
2.4. Item M8:理解各种不同含义的 new 和 delete
如果你想在一块已经获得指针的内存里建立一个对象,应该用 placement new。
1
2
3
4
#include <new>
void* operator new(void *location);
void operator delete(void *memoryToBeDeallocated);
new 和 delete 操作符是内置的,其行为不受你的控制,凡是它们调用的内存分配和释放函数则可以控制。
3. 异常
C 程序员满足于使用错误代码(Error code),C 程序员能够仅通过 setjmp 和 longjmp 来完成与异常处理相似的功能。
3.1. Item M9:使用析构函数防止资源泄漏
你需要对用来操纵局部资源(local resources)的指针说再见。
资源应该被封装在一个对象里,遵循这个规则,你通常就能避免在存在异常环境里发生资源泄漏。
3.2. Item M10:在构造函数中防止资源泄漏
3.3. Item M11:禁止异常信息(exceptions)传递到析构函数外
在有两种情况下会调用析构函数。
- 第一种是在正常情况下删除一个对象,例如对象超出了作用域或被显式地
delete。 - 第二种是异常传递的堆栈辗转开解(stack-unwinding)过程中,由异常处理系统删除一个对象。
不允许异常传递到析构函数外面原因:
- 因为如果在一个异常被激活的同时,析构函数也抛出异常,并导致程序控制权转移到析构函数外,
C++将调用terminate函数。它终止你程序的运行,而且是立即终止,甚至连局部对象都没有被释放。 - 如果一个异常被析构函数抛出而没有在函数内部捕获住,那么析构函数就不会完全运行(它会停在抛出异常的那个地方上)
3.4. Item M12:理解“抛出一个异常”与“传递一个参数”或“调用一个虚函数”间的差异
你调用函数时,程序的控制权最终还会返回到函数的调用处,但是当你抛出一个异常时,控制权永远不会回到抛出异常的地方。
1
2
3
4
5
6
7
8
9
10
11
class Widget { ... };
class SpecialWidget: public Widget { ... };
catch (Widget& w) // 捕获 Widget 异常
{
throw; // 重新抛出异常,让它继续传递
}
catch (Widget& w) // 捕获 Widget 异常
{
throw w; // 传递被捕获异常的拷贝
}
第一个块中重新抛出的是当前异常(current exception),无论它是什么类型。特别是如果这个异常开始就是做为 SpecialWidget 类型抛出的,那么第一个块中传递出去的还是 SpecialWidget 异常,即使 w 的静态类型(static type)是 Widget。
第二个 catch 块重新抛出的是新异常,类型总是 Widget,因为 w 的静态类型(static type)是 Widget。
1
2
3
catch (Widget w) // 通过传值捕获异常
catch (Widget& w) // 通过传递引用捕获异常
catch (const Widget& w) // 通过传递指向 const 的引用捕获异常
把一个对象传递给函数或一个对象调用虚拟函数与把一个对象做为异常抛出,这之间有三个主要区别。
- 异常对象在传递时总被进行拷贝
;当通过传值方式捕获时,异常对象被拷贝了两次。对象做为参数传递给函数时不一定需要被拷贝。
- 对象做为异常被抛出与做为参数传递给函数相比,前者类型转换比后者要少(前者只有两种转换形式,第一种是继承类与基类间的转换。第二种是允许从一个类型化指针(typed pointer)转变成无类型指针(untyped pointer))。
catch子句进行异常类型匹配的顺序是它们在源代码中出现的顺序,第一个类型匹配成功的catch将被用来执行。当一个对象调用一个虚拟函数时,被选择的函数位于与对象类型匹配最佳的类里,即使该类不是在源代码的最前头
3.5. Item M13:通过引用(reference)捕获异常
如果你通过引用捕获异常(catch by reference),你就能避开上述所有问题,不会为是否删除异常对象而烦恼;能够避开 slicing 异常对象;能够捕获标准异常类型;减少异常对象需要被拷贝的数目。
3.6. Item M14:审慎使用异常规格(exception specifications)
例如函数 f1 没有声明异常规格,这样的函数就可以抛出任意种类的异常:
1
extern void f1(); // 可以抛出任意的异常
假设有一个函数 f2 通过它的异常规格来声明其只能抛出 int 类型的异常:
1
void f2() throw(int);
不能抛出任何异常:
1
void f3() throw();
异常规格缺点:
- 编译器仅仅部分地检测异常的使用是否与异常规格保持一致。编译器允许你调用一个函数,其抛出的异常与发出调用的函数的异常规格不一致,这样的调用可能导致你的程序执行被终止。
- 异常规格能导致
unexpected被触发,他们会阻止high-level异常处理器来处理unexpected异常,即使这些异常处理器知道如何去做。
3.7. Item M15:了解异常处理的系统开销
- 你需要空间建立数据结构来跟踪对象是否被完全构造(constructed)(参见条款 M10),你也需要
CPU时间保持这些数据结构不断更新。 - 使用异常处理的第二个开销来自于
try块。如果你使用try块,代码的尺寸将增加5%--10%并且运行速度也同比例减慢。 - 编译器为异常规格生成的代码与它们为
try块生成的代码一样多,所以一个异常规格一般花掉与try块一样多的系统开销。
为了使你的异常开销最小化,只要可能就尽量采用不支持异常的方法编译程序,把使用 try 块和异常规格限制在你确实需要它们的地方,并且只有在确为异常的情况下(exceptional)才抛出异常。如果你在性能上仍旧有问题,总体评估一下你的软件以决定异常支持是否是一个起作用的因素。如果是,那就考虑选择其它的编译器,能在 C++ 异常处理方面具有更高实现效率的编译器。
4. 效率
4.1. Item M16:牢记 80-20 准则(80-20 rule)
80-20 准则说的是大约 20% 的代码使用了 80% 的程序资源;大约 20% 的代码耗用了大约 80% 的运行时间;大约 20% 的代码使用了 80% 的内存;大约 20% 的代码执行 80% 的磁盘访问;80% 的维护投入于大约 20% 的代码上。
用分析器(profiler)程序识别出令人讨厌的程序的 20% 部分,并优化这 20% 代码。
4.2. Item M17:考虑使用 lazy evaluation(懒惰计算法)
从效率的观点来看,最佳的计算就是根本不计算,当你使用了 lazy evaluation 后,采用此种方法的类将推迟计算工作直到系统需要这些计算的结果。如果不需要结果,将不用进行计算。
- 避免不需要的对象拷贝
- 通过使用
operator[]区分出读操作 - 避免不需要的数据库读取操作
- 避免不需要的数字操作。
4.3. Item M18:分期摊还期望的计算
这个条款的核心就是 over-eager evaluation(过度热情计算法):在要求你做某些事情以前就完成它们。
1
2
3
4
5
6
7
template<class NumericalType>
class DataCollection {
public:
NumericalType min() const;
NumericalType max() const;
NumericalType avg() const;
};
我们把跟踪集合最小值、最大值和平均值的开销分摊到所有这些函数的调用上,每次函数调用所分摊的开销比 eager evaluation 或 lazy evaluation 要小。
采用 over-eager 最简单的方法就是 caching (缓存)那些已经被计算出来而以后还有可能需要的值。
4.4. Item M19:理解临时对象的来源
建立一个没有命名的非堆(non-heap)对象会产生临时对象。
- 为了使函数成功调用而进行隐式类型转换
- 函数返回对象时
4.5. Item M20:协助完成返回值优化
以某种方法返回对象,能让编译器消除临时对象的开销,这样编写函数通常是很普遍的。这种技巧是返回 constructor argument 而不是直接返回对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Rational {
public:
Rational(int numerator = 0, int denominator = 1);
int numerator() const;
int denominator() const;
// 一种高效和正确的方法,用来实现返回对象的函数
const Rational operator*(const Rational& lhs, const Rational& rhs)
{
return Rational(lhs.numerator() * rhs.numerator(),
lhs.denominator() * rhs.denominator());
}
};
Rational a = 10;
Rational b(1, 2);
Rational c = a * b; // 在这里调用 operator*
如果你的编译器这样去做,调用 operator* 的临时对象的开销就是零:没有建立临时对象。你的代价就是调用一个构造函数――建立 c 时调用的构造函数。不过你还可以通过把函数声明为 inline 来消除 operator* 的调用开销。
4.6. Item M21:通过重载避免隐式类型转换
让编译器完成这种类型转换是确实是很方便,但是建立临时对象进行类型转换工作是有开销的,而我们不想承担这种开销。
1
2
3
4
5
6
7
8
9
10
// integers 类
class UPInt {
public:
UPInt();
UPInt(int value);
const UPInt operator+(const UPInt& lhs, const UPInt& rhs); // add UPInt and UPInt
const UPInt operator+(const UPInt& lhs, int rhs); // add UPInt and int
const UPInt operator+(int lhs, const UPInt& rhs); // add int and UPInt
};
为什么不重载 const UPInt operator+(int lhs, int rhs); ,在 C++ 中有一条规则是每一个重载的 operator 必须带有一个用户定义类型(user-defined type)的参数。
利用重载避免临时对象的方法不只是用在 operator 函数上。比如在大多数程序中,你想允许在所有能使用 string 对象的地方,也一样可以使用 char*,反之亦然。
4.7. Item M22:考虑用运算符的赋值形式(op=)取代其单独形式(op)
确保 operator 的赋值形式(assignment version)(例如 operator+=)与一个 operator 的单独形式(stand-alone)(例如 operator+ )之间存在正常的关系,一种好方法是后者根据前者来实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class Rational {
public:
Rational& operator+=(const Rational& rhs);
Rational& operator-=(const Rational& rhs);
};
// operator+ 根据 operator+= 实现
const Rational operator+(const Rational& lhs, const Rational& rhs)
{
return Rational(lhs) += rhs;
}
// operator- 根据 operator -= 实现
const Rational operator-(const Rational& lhs, const Rational& rhs)
{
return Rational(lhs) -= rhs;
}
// 方法一:
Rational a, b, c, d, result;
result = a + b + c + d; // 可能用了 3 个临时对象每个 operator+ 调用使用 1 个
// 方法二:
result = a; //不用临时对象
result += b; //不用临时对象
result += c; //不用临时对象
result += d; //不用临时对象
- 第一、总的来说
operator的赋值形式比其单独形式效率更高,因为单独形式要返回一个新对象,从而在临时对象的构造和释放上有一些开销。operator的赋值形式把结果写到左边的参数里,因此不需要生成临时对象来容纳operator的返回值。 - 第二、提供
operator的赋值形式的同时也要提供其标准形式,允许类的客户端在便利与效率上做出折衷选择。
4.8. Item M23:考虑变更程序库
因为不同的程序库在效率、可扩展性、移植性、类型安全和其他一些领域上蕴含着不同的设计理念,通过变换使用给予性能更多考虑的程序库,你有时可以大幅度地提高软件的效率。
4.9. Item M24:理解虚拟函数、多继承、虚基类和 RTTI 所需的代价
虚函数大多数编译器是使用 virtual table 和 virtual table pointers。virtual table 和 virtual table pointers 通常被分别地称为 vtbl 和 vptr。
- 虚函数所需的第一个代价:你必须为每个包含虚函数的类的
virtual talbe留出空间。 - 虚函数所需的第二个代价:在每个包含虚函数的类的对象里,你必须为额外的指针付出代价。
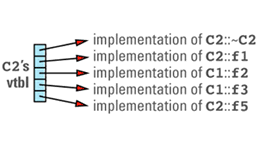
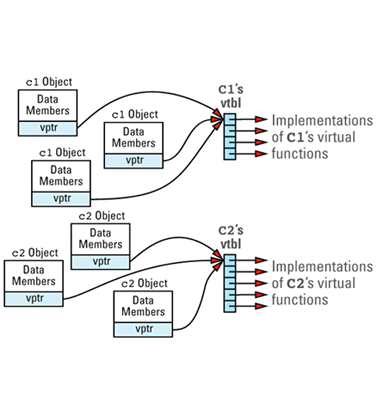
多继承(“恐怖的多继承菱形”(the dreaded multiple inheritance diamond))经常导致使对象变得更大,而且不能使用内联。

运行时类型识别(RTTI)。RTTI 能让我们在运行时找到对象和类的有关信息,所以肯定有某个地方存储了这些信息让我们查询。这些信息被存储在类型为 type_info 的对象里,你能通过使用 typeid 操作符访问一个类的 type_info 对象。 RTTI 被设计为在类的 vtbl 基础上实现。
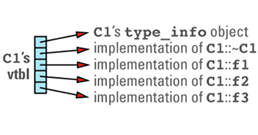
下面这个表各是对虚函数、多继承、虚基类以及 RTTI 所需主要代价的总结:
| 特征 | 增加对象大小 | 增加每个类数据 | 减少内联 |
|---|---|---|---|
| 虚函数 | 是 | 是 | 是 |
| 多重继承 | 是 | 是 | 否 |
| 虚基类 | 是 | 可能 | 否 |
| RTTI | 否 | 是 | 否 |
5. 技巧
5.1. Item M25:将构造函数和非成员函数虚拟化
被派生类重定义的虚函数不用必须与基类的虚函数具有一样的返回类型。如果函数的返回类型是一个指向基类的指针(或一个引用),那么派生类的函数可以返回一个指向基类的派生类的指针(或引用)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class NLComponent {
public:
// declaration of virtual copy constructor
virtual NLComponent * clone() const = 0;
};
class TextBlock: public NLComponent {
public:
virtual TextBlock * clone() const // virtual copy constructor
{ return new TextBlock(*this); }
};
class Graphic: public NLComponent {
public:
virtual Graphic * clone() const // virtual copy constructor
{ return new Graphic(*this); }
};
class NewsLetter {
public:
NewsLetter(const NewsLetter& rhs);
private:
list<NLComponent*> components;
};
NewsLetter::NewsLetter(const NewsLetter& rhs)
{
// 遍历整个 rhs 链表,使用每个元素的虚拟拷贝构造函数,把元素拷贝进这个对象的 component 链表。
for (list<NLComponent*>::const_iterator it = rhs.components.begin();
it != rhs.components.end();
++it) {
// "it" 指向 rhs.components 的当前元素,调用元素的 clone 函数,
// 得到该元素的一个拷贝,并把该拷贝放到这个对象的 component 链表的尾端。
components.push_back((*it)->clone());
}
}
如果没有虚拟的构造函数,那么进行深拷贝时不能确定类型,导致新的对象数据丢失。
5.2. Item M26:限制某个类所能产生的对象数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
template <class BeingCounted>
class Counted
{
public:
class TooManyObjects {}; // 用来抛出异常
static int objectCount() { return numObjects; }
protected:
Counted();
Counted(const Counted& rhs);
~Counted() { --numObjects; }
private:
static int numObjects;
static const size_t maxObjects;
void init(); // 避免构造函数的代码重复
};
template <class BeingCounted>
Counted<BeingCounted>::Counted()
{
init();
}
template <class BeingCounted>
Counted<BeingCounted>::Counted(const Counted<BeingCounted>&)
{
init();
}
template <class BeingCounted>
void Counted<BeingCounted>::init()
{
if (numObjects >= maxObjects)
throw TooManyObjects();
++numObjects;
}
5.3. Item M27:要求或禁止在堆中产生对象
非堆对象(non-heap object)在定义它的地方被自动构造,在生存时间结束时自动被释放,所以只要禁止使用隐式的构造函数和析构函数,就可以禁止在堆中建立对象。
通常对象的建立这样三种情况:
- 对象被直接实例化;
- 对象做为派生类的基类被实例化;
- 对象被嵌入到其它对象内。
如果你想不想让用户在堆中建立 UPNumber 对象,你可以这样编写:
1
2
3
4
5
class UPNumber {
private:
static void *operator new(size_t size);
static void operator delete(void *ptr);
};
如果你也想禁止 UPNumber 堆对象数组,可以把 operator new[] 和 operator delete[] 也声明为 private。
5.4. Item M28:灵巧(smart)指针
5.5. Item M29:引用计数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// base class for reference counted objects
class RCObject
{
public:
void addReference();
void removeReference();
void markUnshareable();
bool isShareable() const;
bool isShared() const;
protected:
RCObject();
RCObject(const RCObject& rhs);
RCObject& operator=(const RCObject& rhs);
virtual ~RCObject() = 0;
private:
int refCount;
bool shareable;
};
// template class for smart
// pointers-to-T objects; T inherit from RCObject
template <class T>
class RCPtr
{
public:
RCPtr(T* realPtr = 0);
RCPtr(const RCPtr& rhs);
~RCPtr();
RCPtr& operator=(const RCPtr& rhs);
T* operator->() const;
T& operator*() const;
private:
T* pointee;
void init();
};
上述两个条款本人觉得是智能指针实现。
5.6. Item M30:代理类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template <class T>
class Array2D
{
public:
class Array1D
{
public:
T& operator[](int index);
const T& operator[](int index) const;
};
Array1D operator[](int index);
const Array1D operator[](int index) const;
};
// 现在,它合法了:
Array2D<float> data(10, 20);
cout << data[3][6]; // fine
Proxy 类可以完成一些其它方法很难甚至不可能实现的行为。
- 多维数组
- 左/右值的区分
- 限制隐式类型转换。
5.7. Item M31:让函数根据一个以上的对象来决定怎么虚拟
6. 杂项
6.1. Item M32:在未来时态下开发程序
- 提供完备的类,即使某些部分现在还没有被使用。如果有了新的需求,你不用回过头去改它们。
- 将你的接口设计得便于常见操作并防止常见错误。使得类容易正确使用而不易用错。例如,阻止拷贝构造和赋值操作,如果它们对这个类没有意义的话。防止部分赋值。
- 如果没有限制你不能通用化你的代码,那么通用化它。例如,如果在写树的遍历算法,考虑将它通用得可以处理任何有向不循环图。
未来时态的考虑增加了你的代码的可重用性、可维护性、健壮性,已及在环境发生改变时易于修改。它必须与进行时态的约束条件进行取舍。太多的程序员们只关注于现在的需要,然而这么做牺牲了其软件的长期生存能力。是与众不同的,是离经叛道的,在未来时态下开发程序。
6.2. Item M33:将非尾端类设计为抽象类
6.3. Item M34:如何在同一程序中混合使用 C++ 和 C
名变换,就是 C++ 编译器给程序的每个函数换一个独一无二的名字。在 C 中,这个过程是不需要的,因为没有函数重载,但几乎所有 C++ 程序都有函数重名。
1
2
3
4
5
6
7
8
9
10
11
// 告诉编译器,这部分代码按C语言的格式进行编译,而不是C++的
#ifdef __cplusplus
extern "C"
{
#endif
/*…*/
#ifdef __cplusplus
}
#endif
如果想在同一程序下混合 C++ 与 C 编程,记住下面的指导原则:
- 确保
C++和C编译器产生兼容的obj文件。 - 将在两种语言下都使用的函数申明为
extern "C"。 - 只要可能,用
C++写main()。 - 总用
delete释放new分配的内存;总用free释放malloc分配的内存。 - 将在两种语言间传递的东西限制在用
C编译的数据结构的范围内;这些结构的C++版本可以包含非虚成员函数。