pugixml指南
pugixml 是一款轻量级 C++ 解析 XML 的程序库。
pugixml
1. 网址
2. 介绍
本文都是根据官方文件 https://pugixml.org/docs/manual.html 翻译并只保留基本介绍和接口说明,版本适用于 V1.11。
2.1. 核心文件
1
2
3
pugiconfig.hpp // 可以根据需要解除注释
pugixml.hpp
pugixml.cpp
2.1.1. 只引用头文件
pugixml 的三个文件,可以只包含头文件 pugixml.hpp,CPP文件不用放到项目中,方法是在 pugiconfig.hpp 中:
1
2
// Uncomment this to switch to header-only version
// #define PUGIXML_HEADER_ONLY
将 PUGIXML_HEADER_ONLY 宏定义注释去掉就可以了。
2.2. XML文档结构
| 名称 | 说明 | 示例 |
|---|---|---|
文档节点 (node_document) | XML树形结构的根,它由几个子节点组成 | |
元素/标签节点 (node_element) | 最常见的节点类型,它表示 XML 元素。元素节点具有名称、属性集合和子节点集合(两者都可能为空) | |
纯字符数据节点 (node_pcdata) | 表示 XML 中的纯文本 | |
字符数据节点 (node_cdata) | 表示以特殊方式引用的 XML 文本,除了 XML 表示之外,CDATA 节点与 PCDATA 节点没有区别 | |
注释节点 (node_comment) | 表示 XML 中的注释 | |
处理指令节点(node_pi) | 表示 XML 中的处理指令 (PI)。PI 节点具有名称和可选值,但没有子节点/属性 | <?name value?> |
声明节点(node_declaration) | 表示 XML 中的文档声明 | <?xml version=”1.0”?> |
文档类型声明节点(node_doctype) | 表示 XML 中的文档类型声明。文档类型声明节点有一个值,对应整个文档类型内容; 一个文档中只能有一个文档类型声明节点;它应该是最顶层的节点 | <!DOCTYPE greeting [ <!ELEMENT greeting (#PCDATA)> ]> |
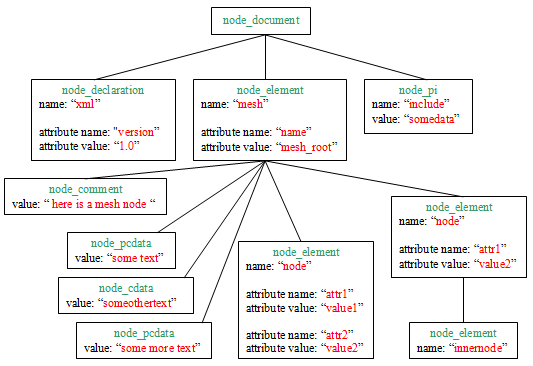
一个完整的 XML 文档示例和相应树图表示
1
2
3
4
5
6
7
8
9
10
11
12
<?xml version="1.0"?>
<mesh name="mesh_root">
<!-- here is a mesh node -->
some text
<![CDATA[someothertext]]>
some more text
<node attr1="value1" attr2="value2" />
<node attr1="value2">
<innernode/>
</node>
</mesh>
<?include somedata?>
2.3. C++接口
所有
pugixml类和函数都位于pugi命名空间中;您必须使用明确的限定名称,即通过指令pugi::xml_node访问相关符号。此后本文档中的所有声明都将省略命名空间;所有代码示例都将使用完全限定名称,直接使用pugi::xml_node或者using namespace pugi;指定作用域。
2.3.1. 节点类型
尽管有多种节点类型,但只有三个 C++ 类表示树(xml_document、xml_node、xml_attribute);某些操作xml_node仅对某些节点类型有效。
2.3.1.1. xml_document
xml_document是整个文档结构的所有者;它是一个不可复制的类。接口xml_document由加载功能、保存功能和所有 xml_node 接口组成,允许文档检查和/或修改。注意xml_document是xml_node的子类,xml_node不是多态类型;继承只是为了简化使用。
xml_document的默认构造函数将文档初始化为只有一个根节点(文档节点)的树。然后,您可以使用树修改函数或加载函数使用数据填充它;所有加载函数都会破坏前一棵树并占用所有内存,这会使该文档的现有节点/属性句柄处于无效状态。如果要销毁之前的树,可以使用xml_document::reset函数;它会破坏树并将其替换为空树或指定文档的副本。xml_document的析构函数也会破坏树,因此文档对象的生命周期应该超过指向树的任何节点/属性句柄的生命周期。
2.3.1.2. xml_node
xml_node是文档节点的句柄;它可以指向文档中的任何节点,包括文档节点本身。所有类型的节点都有一个通用接口;可以通过该xml_node::type()查询实际的节点类型。这xml_node只是实际节点的句柄,而不是节点本身,您可以有多个xml_node句柄指向同一个底层对象。销毁xml_node句柄不会破坏节点,也不会将其从树中删除。xml_node的大小等于指针的大小。
2.3.1.3. xml_attribute
xml_attribute 是 XML 属性的句柄;它具有与 相同的语义 xml_node,即可以有多个 xml_attribute 句柄指向同一个底层对象,并且有一个特殊的 null 属性值,它会传播到函数结果。
2.3.2. 关键类及函数
2.3.2.1. xml_attribute
| 函数 | 说明 |
|---|---|
| empty | 判断节点属性是否为空 |
| operator | 重载符号判断节点大小 ==, !=, <, >, <=, >= |
| next_attribute | 下一个节点属性 |
| previous_attribute | 上一个节点属性 |
| name | 获取名称 |
| value | 获取值 |
| as_{value} | 值转换成对应类型,string(const char_t*), int, uint, double, float, bool, llong, ullong |
| set_name | 设置名称 |
| set_value | 设置值,类型同上 |
| operator | 重载符号赋值构造对应类型,string(const char_t*), int, uint, double, float, bool, llong, ullong |
2.3.2.2. xml_node
| 函数 | 说明 |
|---|---|
| empty | 判断节点属性是否为空 |
| operator | 重载符号判断节点大小 ==, !=, <, >, <=, >= |
| next_attribute | 下一个节点属性 |
| previous_attribute | 上一个节点属性 |
| name | 获取名称 |
| value | 获取值 |
| parent | 获取该节点父节点 |
| first_child | 获取该节点第一个子节点 |
| last_child | 获取该节点最后一个子节点 |
| next_sibling | 获取该节点后一个子节点,可以根据指定名称获取 |
| previous_sibling | 获取该节点前一个子节点,可以根据指定名称获取 |
| first_attribute | 获取该节点第一个节点属性 |
| last_attribute | 获取该节点最后一个节点属性 |
| children | 获取该节点的所有子节点,可以根据指定名称获取 |
| attributes | 获取该节点的属性所有子属性,可以根据指定名称获取 |
| child | 获取该节点的指定名称子节点 |
| attribute | 获取该节点的属性指定名称子属性 |
| find_child_by_attribute | 根据属性查找节点 |
| child_value | 返回具有类型node_pcdata或node_cdata的第一个子节点的值; |
| text | 获取该节点之间的文本 |
| begin | 迭代器,第一个节点 |
| end | 迭代器,最后一个节点 |
| attributes_begin | 迭代器,第一个属性 |
| attributes_end | 迭代器,最后一个属性 |
| set_name | 设置名称 |
| set_value | 设置值 |
| append_child | 添加子节点 |
| append_attribute | 添加属性 |
| remove_child | 移除子节点 |
后面就是一些对节点和节点属性的增加、删除、查找指定路径操作,详情查看头文件或者查看官方文档,这里不完全。
2.3.2.3. xml_document
| 函数 | 说明 |
|---|---|
| reset | 它会破坏树并用空的一个或指定文档的副本替换它 |
| load_{value} | 加载数据类型,istream, string, file, buffer |
| save | 保存到数据流中 |
| save_file | 保存到文件当中 |
加载有默认编码可以自定义,保存也有默认格式可以自定义。
2.3.2.4. xml_parse_result
| 函数 | 说明 |
|---|---|
| description | 解析结果描述 |
可以根据解析返回结果 xml_parse_status status (枚举类型)判断解析是否成功,查看失败原因。
2.3.2.5. xml_text
节点之间的文本。
| 函数 | 说明 |
|---|---|
| empty | 判断节点文本是否为空 |
| xml_text::get() | 获取文本内容 |
| as_{value} | 值转换成对应类型,string(const char_t*), int, uint, double, float, bool, llong, ullong |
| set | 设置文本内容 |
| operator | 重载符号赋值构造对应类型,string(const char_t*), int, uint, double, float, bool, llong, ullong |
| data | 获取文本内容,text().data().value() 等同于 text().get() |
2.3.2.6. xpath_node
XPath 使用路径表达式在 XML 文档中选取节点。没做深入研究,感兴趣的可以自行查看官方文档。
3. 使用
3.1. 简单使用
(1)读取文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1. 声明文档
pugi::xml_document doc;
2. 加载数据
2.1 加载字符串 load_string(str);
2.2 加载文件 load_file(filepath);
3. 获取数据
3.1 依次节点解析
3.1.1 获取节点 pugi::xml_node node = doc.child("root") // [root] 为依次想获取的名称
3.1.2 读取数据(可以获取不同类型的数据)
3.1.2.1 括号中数据 node.attribute("ip").as_string()
3.1.2.2 括号间数据 node.text().as_int()
3.2 xpath解析
3.2.1 获取单个路径 pugi::xpath_node xpath = doc.select_node(pugi::xpath_query("/root/host"));
3.2.2 获取全部路径 pugi::xpath_node_set xpaths = doc.select_nodes(pugi::xpath_query("/root/host"));
3.2.3 转换格式 pugi::xml_node node = xpath.node();
3.2.4 同理读取
(2)写入文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1. 声明文档
pugi::xml_document doc;
2. 声明前缀
pugi::xml_node pre = doc.append_child(pugi::node_declaration);
pre.append_attribute("version") = "1.0";
pre.append_attribute("encoding") = "utf-8";
3. 创建节点
pugi::xml_node root = doc.append_child("root");
// 增加注释节点
pugi::xml_node node_comment = root.append_child(pugi::node_comment);
// 增加普通节点
pugi::xml_node node_students = root.append_child("students");
4. 保存数据
doc.save_file("write.xml", "\t", 1U, pugi::encoding_utf8);
3.2. 说明
pugixml 默认解析模式包括元素、PCDATA 和 CDATA 部分被添加到 DOM 树中,这其中不包含注释、头部声明、文档类型。
1
2
3
4
5
6
7
8
9
// The default parsing mode.
// Elements, PCDATA and CDATA sections are added to the DOM tree, character/reference entities are expanded,
// End-of-Line characters are normalized, attribute values are normalized using CDATA normalization rules.
const unsigned int parse_default = parse_cdata | parse_escapes | parse_wconv_attribute | parse_eol;
// The full parsing mode.
// Nodes of all types are added to the DOM tree, character/reference entities are expanded,
// End-of-Line characters are normalized, attribute values are normalized using CDATA normalization rules.
const unsigned int parse_full = parse_default | parse_pi | parse_comments | parse_declaration | parse_doctype;
所以要解析注释、头部声明、文档注释时,使用 parse_full。
3.3. 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
#include <iostream>
#include "pugixml.hpp"
// 字符串解析
void demo1()
{
const char* str = "<?xml version=\"1.0\" encoding=\"GBK\"?><root><host ip=\"192.168.1.1\" port=\"80\" /></root>";
// 定义文档
pugi::xml_document doc;
// 默认 "rb" 加载文档
pugi::xml_parse_result result = doc.load_string(str);
if (!result)
{
std::cout << "load fail..." << std::endl;
return;
}
// 读取节点,一般先默认读取根节点
pugi::xml_node root = doc.child("root");
// 循环读取节点(读取中间文本数据)
// 采用节点查找下一个节点
pugi::xml_node host = root.child("host");
printf("IP[%s] PORT[%d]\n", host.attribute("ip").as_string(), host.attribute("port").as_int());
}
// 文件读取解析
void demo2()
{
// 定义文档
pugi::xml_document doc;
// 默认 "rb" 加载文档
pugi::xml_parse_result result = doc.load_file("read.xml", pugi::parse_full);
if (!result)
{
std::cout << "load fail..." << std::endl;
return;
}
// 读取声明
pugi::xml_node declaration = doc.child("xml");
std::cout << declaration.attribute("version").as_string() << std::endl;
std::cout << declaration.attribute("encoding").as_string() << std::endl;
// 读取节点,一般先默认读取根节点
pugi::xml_node root = doc.child("root");
// 1. 循环读取节点(读取中间文本数据)
// 采用节点查找下一个节点
pugi::xml_node host = root.child("hosts1").child("host");
for (host.first_child(); host; host = host.next_sibling())
{
printf("[next_sibling ]: IP[%s] PORT[%d]\n", host.attribute("ip").as_string(), host.attribute("port").as_int());
}
// 2. 循环读取节点(读取 <> 中数据)
// 采用节点迭代器
pugi::xml_object_range<pugi::xml_node_iterator> hosts = root.child("hosts2").children();
pugi::xml_node_iterator host2 = hosts.begin();
for (host2; host2 != hosts.end(); host2++)
{
printf("[xml_node_iterator]: IP[%s] PORT[%d]\n", host2->child("ip").text().as_string(), host2->child("port").text().as_int());
}
// 3. xpath
pugi::xpath_node_set xpath_hosts = doc.select_nodes(pugi::xpath_query("/root/hosts1/host"));
for (pugi::xpath_node xpath_host : xpath_hosts)
{
pugi::xml_node node_host = xpath_host.node();
printf("[xpath_node ]: IP[%s] PORT[%d]\n", node_host.attribute("ip").as_string(), node_host.attribute("port").as_int());
}
}
// 写入文件
void demo3()
{
pugi::xml_document doc;
// 声明
pugi::xml_node pre = doc.append_child(pugi::node_declaration);
pre.append_attribute("version") = "1.0";
pre.append_attribute("encoding") = "utf-8";
// 创建节点
pugi::xml_node root = doc.append_child("root");
// 增加注释节点
pugi::xml_node node_comment = root.append_child(pugi::node_comment);
node_comment.set_value("all students info");
// 增加普通节点
pugi::xml_node node_class = root.append_child("class");
pugi::xml_node node_className = node_class.append_child("className");
node_className.text().set("土木1702班");
for (size_t i = 0; i < 10; ++i)
{
pugi::xml_node nodeStudent = node_class.append_child("student");
// 增加属性
char name[128] = { 0 };
snprintf(name, 128, "student_%02d", (int)i);
nodeStudent.append_attribute("name").set_value(name);
nodeStudent.append_attribute("score").set_value(100 - i);
}
doc.save_file("write.xml", "\t", 1U, pugi::encoding_utf8);
}
int main()
{
// 字符串解析
// demo1();
// 文件读取解析
// demo2();
// 写入文件
demo3();
return 0;
}